Rules
You are permitted to use a compiler (or any part of llvm/gcc/etc.) for the whole exam. You may spend up to 24 hours of active work on the exam. This time does not have to be contiguous.
Setup
Like usual, you should register for the assignment by going to https://grinch.caltech.edu/register which will create you a repository on gitlab with the starter code.
The open-ended questions in this document are part of your grade on this final. Make sure to submit your answers on Gradescope!!! You may submit as many times as you want.
Written Questions
Heap and Stack (10 points)
typedef struct {
int *input;
size_t idx;
} arg_t;
void *do_it(void *_arg) {
arg_t *arg = _arg;
printf("%d\n", arg->input[arg->idx]);
return NULL;
}
int main() {
int input[10];
for (size_t i = 0; i < 10; i++) {
input[i] = i;
}
pthread_t tids[10];
for (size_t i = 0; i < 10; i++) {
arg_t arg = {.input=input, .idx=i};
pthread_create(&tids[i], NULL, do_it, &arg);
}
for (size_t i = 0; i < 10; i++) {
pthread_join(tids[i], NULL);
}
}
Segmentation Fault (10 points)
Here is a “simple” program:
#include <stdio.h>
int main() {
int *p = NULL;
printf("Value is: %d\n", *p);
return 0;
}
This program is compiled to a file named prog, which is then run from the command-shell via the command ./prog. When you run it, it completes in
a way that you may have seen once or twice in CS 24. In this question, you will enumerate all steps in the program’s execution from beginning to end.
The goal of this question is to demonstrate you understand how the various mechanisms of your system work.
Quicksort (20 points)
A program needs to sort a number of data records, each of which are 128 bytes in size. The first 32 bytes are a string key that the records are sorted on;
the records must be ordered by increasing key value, lexicographically. The records to be sorted are stored in one contiguous array of memory. The
sorting will be done by the C Standard Library implementation of quick-sort, called qsort. You can learn more about how the function is called via
the qsort man page. The most relevant detail is that qsort’s last argument is a function that specifies how to compare the items being sorted;
this allows qsort to sort any array we might give it.Three approaches are considered for use. To evaluate these approaches, three test programs
have been written to measure the performance of each approach as we scale the number of records being sorted. Then, we can also make pretty plots.
Approaches
Approach 1: Sort Records In-Place
The first approach is to simply sort the records themselves, in-place. This seems like a terrible idea because the 128-byte records themselves will be moved around and reordered as the sort progresses. A lot of data will be moved. Nonetheless, we will give it a try. Note that to compare the records, we directly access the records and compares two records’ keys.
Approach 2: Sort Pointers to Records
The second approach is to leave the records themselves where they are, and create an array of pointers to the records. Then, instead of moving around the records themselves, we simply rearrange the array of pointers-to-records. Once qsort is done, we can traverse the array of pointers, and each pointer will tell us the next record in order.
Note that to compare the records, this time we are sorting are record-pointers; so, the compare function receives pointers-to-pointers-to-records. Thus, it must dereference the pointers twice to get to the records’ keys.
Intuitively, this seems like it should be much faster than the first approach, because we are only reordering the pointers, not the records themselves.
Approach 3: Sort “Record Info” Objects
The third approach blends the two above approaches by creating a special ``record info’’ type:
const int KEY_PREFIX_SIZE = 8;
typedef struct recinfo_t {
char key_prefix[KEY_PREFIX_SIZE];
record_t *record;
} recinfo_t;
An array of these record-info objects is then built against the records themselves; each record-info stores the first 8 bytes of the record’s key, and also a pointer to the record itself. The array of record-info objects is sorted by qsort; the comparison function uses the details available through the record-info objects to determine the ordering of the records.
Intuitively, this seems like it should be faster than moving around the large records themselves, but perhaps slower than the second approach where we sort an array of pointers to records.
Test Results
The three approaches were tested on a computer with these memory specifications:
- Intel64 x86 processor; 64-bit data bus
- 32KiB L1 data cache, 64B blocks
- 256KiB L2 data cache, 64B blocks
- 4MiB L3 data cache, 64B blocks
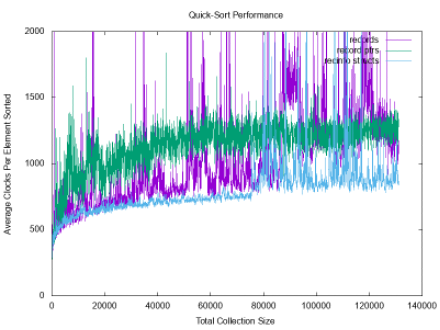
The following graph was produced, comparing the performance of the three approaches.
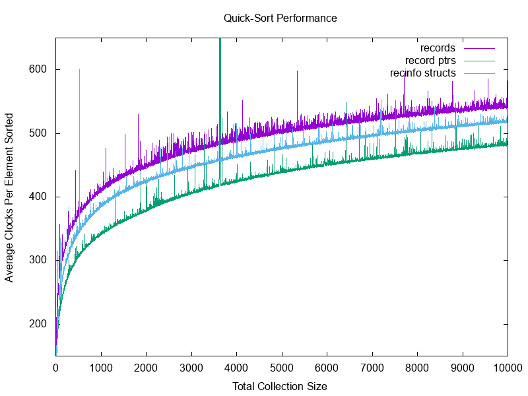
Given that quick-sort is O(N log(N)) average-case, it makes sense that plotting the clocks-per-element (total time / total number of elements N) would follow a log(N) curve. Furthermore, the relative behaviors of the approaches are consistent for N < 10,000:
- the record-pointer approach (green) is fastest
- the record-info approach (blue) is second fastest
- the record approach (purple) is slowest
Finally, consider this graph generated from another trial run of the sorting algorithms:
Programming Question
Introduction
You’ve used asan…it prints error messages when bad stuff happens. In this miniproject, you’ll be implementing a mini
version of asan. We’ve provided you with a partial implementation of a “bump allocator” malloc. Although this may look similar to the malloc project,
we’re actually asking you to do something very different here. We no longer care about utilization or throughput at all. In fact, the final version
of the project will still make no attempt to reuse memory after it’s been allocated. Instead, we will focus on user program correctness. Your malloc,
like asan, will report various errors user code might have made while running. In particular, the types of errors we will focus on are:
- Invalid Free
- Double Free
- Memory Leak
- Invalid Heap Addresses
We’ll tackle these one at a time. Each individual feature has its own set of tests, and you will get credit for whatever subset of the features you implement. The last one is by far the hardest.
malloc with mmap (10 points)
Here is a brief description of the provided (partial) malloc implementation:
Allocations begin from the address
START_PAGEand are always multiples ofsizeof(page_t). The header is a single page before the first page of the payload with three (consecutive) pieces of data:
- A “magic number”:
0x0123456789ABCDEF(of typesize_t)- The exact size requested by the user (of type
size_t). Do NOT round or edit this size. Since part of our implementation will determine if an invalid heap address was accessed, we will need to know this information later.- An allocated flag (of type
bool) Notably, we are not bothering to compress any of this information into a singlesize_t, because we do not care about utilization.We maintain the invariant that the global variable
current_pagepoints to the page after the last page we’ve allocated usingmalloc. We ignore alignment requirements of the returnedpayloadpointer. However, we insist that end of the payload is page aligned. That is, the remainder of thepayloadthat does not make up a full page begins at the end of the first page of the allocation. This will be necessary for the last part.
As written, the provided implementation of malloc calls a few helper functions which are not yet written. Your job in this stage is to write the two following unimplemented functions:
-
void set_header(page_t *header_page, size_t size, bool is_allocated)Sets the contents of the beginning of the provided
header_pageto the three pieces of data as described in the above description of themallocimplementation. -
void *get_payload(page_t *header_page, size_t size)Given a
header_page,get_payloaddetermines the beginning of the actual allocated bytes. As mentioned above, it must be the case that the very end of the allocation be at the very end of a 4096-byte page.
Task 1.
Implement set_header and get_payload.
To run the tests for this part, you should run make test1.
Double Frees (5 points)
The provided implementation of free does nothing. In this stage, you will (1) mark the blocks as unallocated, and (2) check for double frees.
We have provided a function for you to call to report a double free and crash the program:
void report_double_free(void *allocation, size_t allocation_size)
Reports a “double free” (i.e., a user call to free with a “payload” that was previously allocated but is no longer allocated) and exits the program
with a special error code.
Task 2.
Implement a first pass at the free function by:
- Finding the header of the provided payload pointer.
- Checking if the header indicates the block is already free, and calling
report_double_freeif it is. - Setting the header to indicate that the block is free.
To run the tests for this part, you should run make test2.
Invalid Frees (5 points)
Currently, your free code assumes that the provided pointer is actually one that was returned by malloc. A user might make a mistake and send in an invalid pointer.
In this stage, you will check (to the best of your ability) that the pointer provided to free was originally returned by malloc. In the case of an error, you should call
the provided report_invalid_free function:
void report_invalid_free(void *address)
Reports an “invalid free” (i.e., a user call to free with a payload that was not previously allocated) and exits the program
with a special error code.
Task 3.
Augment your free implementation from the previous task to check if the ptr provided to free is actually a pointer returned by malloc before checking if it’s a double free.
You should check for the following two possibilities for an invalid pointer:
- The pointer is not in the range of allocated pages at all.
- The page before the pointer does not seem to be a header. Check this by verifying that the beginning of the header page is exactly the magic number you put there in
set_headerAND that the pointer is actually the beginning of the payload.
To run the tests for this part, you should run make test3.
Leak Checking (15 points)
The atexit function takes in a function pointer which gets executed when exit is called before actually exiting. This can be useful if you want to clean up (or, in our case, check)
something before the program exits. In this stage, you will implement check_for_leaks, which has been installed by atexit, to determine if a user program forgot to free memory and thus
has a memory leak. In the case of a memory leak, you should call the provided report_memory_leak function:
void report_memory_leak(void *allocation, size_t allocation_size)
Reports a “memory leak” (i.e., a situation in which there is memory that is still allocated after the user program has finished running) and exits the program with a special error code.
Task 4.
Write check_for_leaks by reporting the first malloc that did not have a corresponding free.
To run the tests for this part, you should run make test4.
Invalid Memory Accesses (25 points)
The final task is quite a bit more involved than the others. In this task, you will use mprotect and a SIGSEGV handler to determine if an invalid read or write has happened on the heap.
In the case of an invalid heap access, you should call the provided report_invalid_heap_access function:
void report_invalid_heap_access(void *address)
Reports an “invalid heap access” (i.e., a memory read or write to a location that is part of the “heap”, but was not part of a currently allocated block) and exits the program with a special error code.
Since you will be catching all Segmentation Faults, you’ll also have to respond to errors the user makes that are not invalid heap accesses; in such cases, you should call the
provided report_seg_fault function:
void report_seg_fault(void *address)
Reports a Segmentation Fault that was not an invalid heap access and exits the program with a special error code.
Task 5.1.
Until now, the entire “heap” (allocated by mmap in asan_init) has been readable and writable. The first change you should make is to make this memory protected from reads and writes
so the default is that unallocated memory is not either. That is, replace PROT_READ | PROT_WRITE in asan_init with PROT_NONE to make the entire heap unaccesible to start.
This will, of course, break our malloc implementation, because the user won’t be able to use any memory that they’ve allocated!
To fix this, you will need to set the payload pages (NOT the header page) allocated by malloc calls to readable and writable. You can use the
mprotect function to do this with prot = PROT_READ | PROT_WRITE.
Note that you will need to unprotect the header page to be able to write to or read from it. Make sure to re-protect it after you’ve edited it. The user should not be able to access it.
Task 5.2.
The next step is to modify free to “claim back” the payload by calling mprotect function to do this with prot = PROT_NONE.
Note that you will need to unprotect the header page to be able to write to or read from it. Make sure to re-protect it after you’ve edited it. The user should not be able to access it.
Task 5.3.
Now that a SIGSEGV will be caused when a user accesses memory they shouldn’t, write a SIGSEGV handler that reports either an invalid heap access or a seg fault.
To differentiate between an invalid heap access and just a “regular” Segmentation Fault, you should simply check whether or not the address of the access was between START_PAGE and current_page + 1.
To do this, you will need the address that caused the Segmentation Fault. If you use the more complicated signal handler setup (that you used in meltdown), the siginfo_t * argument has an
“si_addr” field which contains this address.
Task 5.
To run the tests for this part, you should run make test.
Did you remember to submit your answers to the OpenEnded questions on Gradescope???